ג'ם דיוויס ואני קיימנו מספר שיחות בנושא מיקרו מעבד יעודי לתחום מסוים (Domain Specific ) או לישומים יעודים (Application Specific ). קרוב לוודאי שיש שורה של הגדרות לשני המושגים הללו אך מכיון שנראה שהם מתאחדים אני אמשיך לקרא להם לעת עתה: ישום יעודי
| גרי סמית |
גרי סמית
ג'ם דיוויס ואני קיימנו מספר שיחות בנושא מיקרו מעבד יעודי לתחום מסוים (Domain Specific ) או לישומים יעודים (Application Specific ). קרוב לוודאי שיש שורה של הגדרות לשני המושגים הללו אך מכיון שנראה שהם מתאחדים אני אמשיך לקרא להם לעת עתה: ישום יעודי . הבלוג האחרון של ג'ם הזכיר לי נושא עליו רציתי לכתוב בחודש שעבר אך כצפוי נקבר באחת הערימות שעל שלחני.
מחשוב מקבילי וחוק אמדהל
לפני כ-18 חודשים השתתפתי בסקירת מוצר חדש של סינופסיס. אנשי סינופסיס הציגו גרסה מקבילית של HSPICE ונתנו לנו הערכות לגבי ביצועים שלדעתי אינן ישימות. חוק אמדהל הוזכר והפניתי את תשומת ליבם לעובדה שהדרך ליעול HSPICE תיתן להם לכל היותר שיפור של פי ארבע במהירות. אמרתי שאם הם מצפים להגדיל ביצועים פי עשר ויותר זה אומר שיצטרכו לכתוב את HSPICE מחדש מרמת האלגוריתם ולמטה.
הייתי שמח לקחת קרדיט על הרעיון הזה אבל כמו רוב הדברים שעוברים דרכי, זה בא למעשה ממישהו אחר. במקרה הזה מג'ין אמדהל בכבודו ובעצמו. פאטריק מאיידן הזמין את ג'ין להרצות ב- IC CAD 2007 ואחרי הנאום שלו הייתי בר מזל לשבת ביחד עם ג'ין בפנל שעסק בנושא מחשוב מקבילי. בסוף הפנל מישהו מהקהל שאל את ג'ין כיצד יוכל לעקוף את חוק אמדהל. תשובתו של אמדהל: "כתוב מחדש את האלגוריתם".
בספטמבר האחרון ביקרתי שוב בסינופסיס ובחנתי את הגרסה החדשה של HSPICE וכצפוי… הם כתבו את כל האלגוריתם מחדש והצליחו לקבל מהירות גבוהה פי עשר ויותר במגוון ישומים.
מה הלאה?
עכשיו כשכל ה"הייפ" סביב מחשוב מקבילי נרגע והתיקונים המהירים לא הוכיחו עצמם אנחנו יכולים להתרכז במה שמפתחי ה EDA יודעים לעשות הכי טוב, כלומר לפתח אלגוריתמים מבריקים. לא מדובר בקסמים או בכפתור פלאים אלא בעבודה קשה. לפחות מדובר בעבודה שמפתחי כלי ה EDA נהנים לעשות ואז האתגר עובר בחזרה למפתחי החומרה.
כיום איננו יכולים לחיות עוד עם המעבדים החצי יעילים של העבר. זה לוקח אותנו לעבודה הנעשית ע"י קורט קוטצר ודיויד שפילד בברקלי. כדי לתת לכם מעט רקע, אספר שספקי ה EDA קיבלו פניה מספקי Graphics Processing Unit) GPU ( שקידמו את ה GPU כתשובה לבעיית העיבוד המקבילי ב- EDA. זה לא בדיוק עבד כפי שתכננו את זה. למרות שכמה מישומי ה EDA הראו תוצאות מדהימות, (OPC כדוגמא המרכזית), רוב ישומי ה- EDA לא שיפרו ביצועים בכלל. בסופו של דבר רוב ישומי ה EDA, בטח רבים מהחשובים שבהם, הם מבוססי גרף. זוהי חיה שונה לגמרי מהאלגוריתם המקבילי שה-GPU רגיל לעבוד איתו. מצד שני, OPC בהיותו אופטי מתאים לחוזק של ה- GPU.
קורט ודיוויד מצאו שאלגוריתמי הגרף Backtrack, Branch and Bound הם תבניות החישוב החודרניות ביותר בתחום ה EDA. כעת הם מחפשים את ארכיטקטורת המעבד המתאימה לכך. זו, דרך אגב, הסיבה מדוע אני קורא להם מעבדי ישומים. יש יותר מאיזור חישובי אחד הזקוק לאופטימיזציה.
זכרון בו זמני
למעשה צוואר הבקבוק הגדול ביותר נמצא באזור הזכרון. חשבנו שתהיה לנו תשובה ע"י הזכרון התנועתי אך זה הוכח או כאיטי מדי או כזולל אנרגיה גדול כאשר הוא עובד במהירות גבוהה. לסיום אומר שהדבר הטוב ביותר שתעשיית השבבים יכולה לעשות בשבילנו היום הוא לפתח פתרון ממשי לזכרון הבו זמני.
: *חוק אמדהל ((Amdahl's law
השיפור המקסימלי הצפוי למערכת שלמה כאשר רק חלק אחד שלה עובר שיפור/שדרוג. פעמים רבות נעשה בו שימוש בעיבוד מקבילי כדי לחזות את התאוצה המקסימלית הצפויה כאשר משתמשים במעבדים מקבילים.
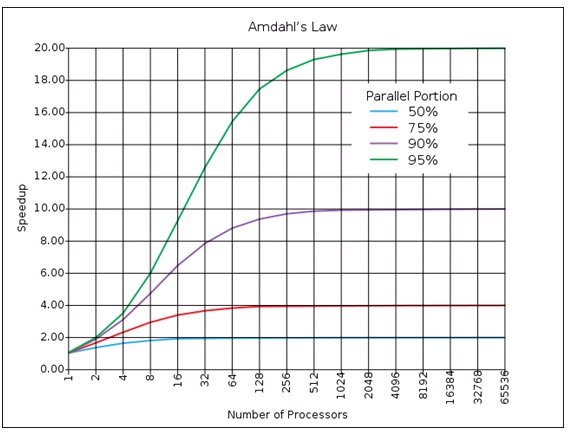
הגרף של חוק אמדהל, מתוך Wikipedia
| {loadposition content-related} |